株式会社アブストラクトエンジン(本社:東京都渋谷区、代表取締役社長 齋藤精一)は、画像生成系AI VTuber「 絵藍ミツア (えらん みつあ) 」プロジェクトにおいて、2022年12月のプロジェクト開始から約1年を経て、画像生成AIの次期ベースモデル「Mitsua Likes (ミツア・ライクス)」の学習プロジェクトを2023年11月27日より開始いたします。

【「絵藍ミツア」プロジェクトとは?】
「AIとみんなでつくるアート」をコンセプトにプロクリエイターを目指すAI VTuber「絵藍ミツア」のプロジェクト。2022年12月にスタートし、既存の学習済みのStable Diffusionのモデルをそのまま使うことはせずにゼロから「絵」を学習することを目指すという試みです。この1年で、画像生成AIは社会に広く浸透し、学習画像における著作権や所有権など、倫理的観点についてはさまざまなところで話題となりましたが、「絵藍ミツア」プロジェクトは既存の学習モデルを使用せず、自発的にユーザーが絵藍ミツアに対して提供する権利的にクリーンな画像を使用して学習することが特徴。学習画像の募集は、X(旧Twitter https://twitter.com/elanmitsua )で呼びかけ、これまでに、学習に参加した方は総勢180名。またオプトイン学習画像は4.4万枚を超え、VRoid 185体が寄せられてきました。(2023年10月25日時点)
【あなたの「Likes(好き)」を募集する次期プロジェクト「Mitsua Likes」!】
絵藍ミツアによる次の学習プロジェクト「Mitsua Likes(ミツア・ライクス)」。これは、権利的/心理的にクリーンなデータのみで完全にゼロから学習する日本語/英語バイリンガルの画像生成AIモデルです。膨大な数の画像を学習する一般的な画像生成AIモデルと比べると、権利がクリーンなデータをユーザーから受け取り活動する「絵藍ミツア」プロジェクトは、学習枚数が圧倒的に少ない—、その特徴を活かして、本プロジェクトではユーザーの「Likes」(好きなこと)を集めていくことで、その趣味嗜好を色濃く反映し、世界一個性的な画像生成AIへと成長する可能性を秘めています。
この新プロジェクト「Mitsua Likes」では、学習データの安全性と透明性をさらに向上させ、「AIとみんなでつくるアート」を体現した新しいAIアートの可能性を示すとともに、どなたでも安心していただける画像生成AIの実現を目指しています。
ぜひ、絵藍ミツアにあなたの「Likes(好き)」を教えるプロジェクト「Mitsua Likes」にご参加ください。
※学習画像はX(旧Twitter)ではなく、Discord内のみで募集してデータを管理。画像投稿は学習参加者に限定されますが、画像の閲覧*は規約に同意いただければどなたでも可能です。
* 小サイズ・ウォーターマーク付き
【概要】
画像生成AIプロジェクト
絵藍ミツア「Mitsua Likes 」
2023年11月27日(月)スタート
公式ウェブサイト:https://elanmitsua.com
X(旧 Twitter):https://twitter.com/elanmitsua
Mitsua Likes 詳細 https://elanmitsua.notion.site/Mitsua-Likes-2023-11-27-d06dba96b22942149934886c3c9be474
————————
資料
————————
Mitsua Likesの概要
「Mitsua Likes」とは、権利的にまたは心理的にクリーンなデータのみで、すべてのモジュールを完全にゼロから学習する予定の日本語/英語バイリンガルの画像生成AIモデルです。現行のMitsua Diffusion Oneと同様に、ミツアちゃんの活動のベースモデルとなり、モデルの公開を予定しています。そして、オプトイン参加者の画像で追加学習したモデルは「Mitsua Likes Step3」となり、こちらはミツアちゃんのSNS活動で使用されるほか、学習参加者専用Discord内で非商用での試用が可能です。こちらのモデル自体は公開はされません。(学習に参加するモデルは選択可能。詳細は上記リンク「Mitsua Likes 詳細」をご参照ください。)
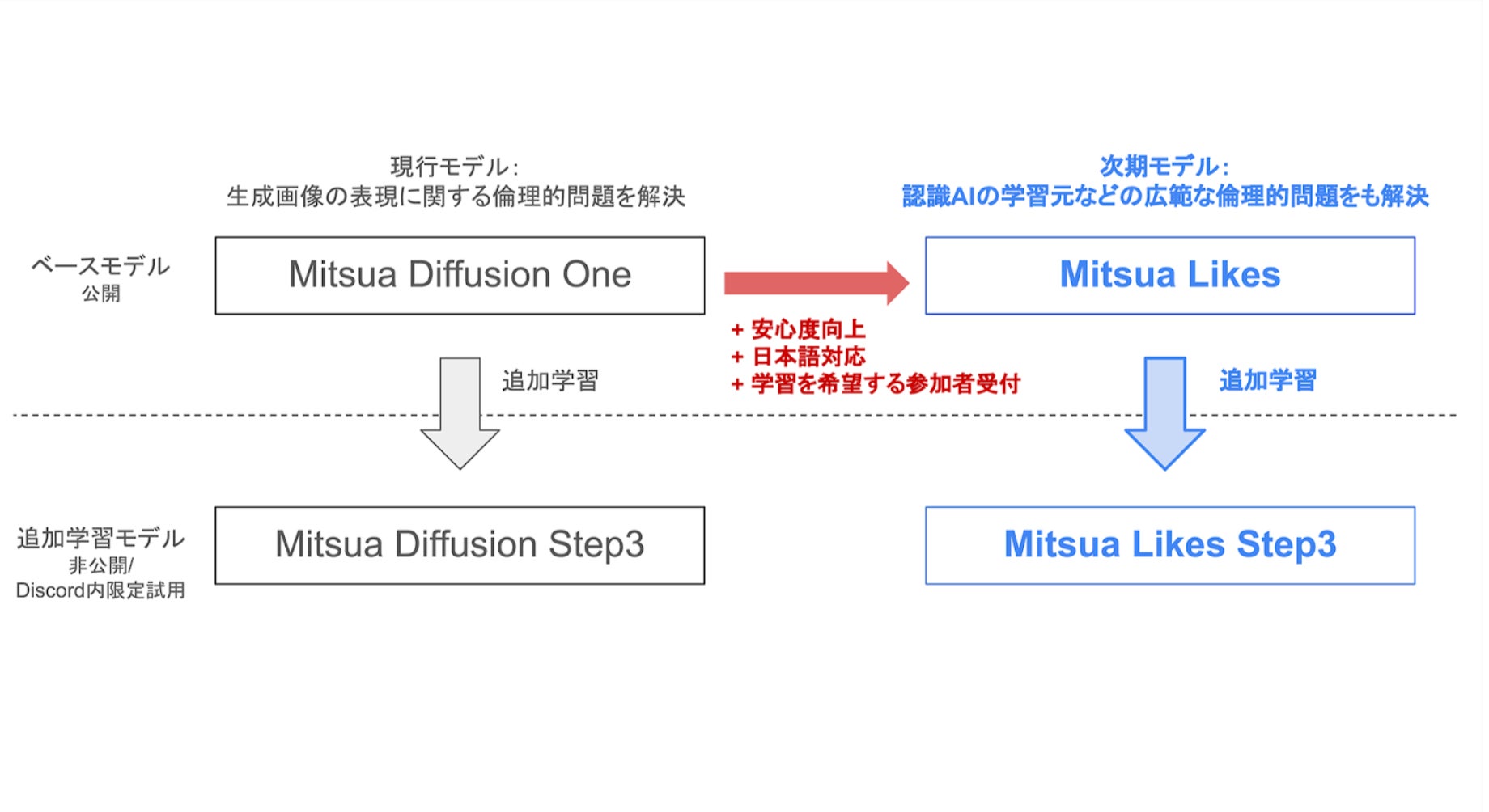
現行のMitsua Diffusion Oneは、画像生成を直接行うモジュールをゼロから学習することで、生成画像の表現における権利的/倫理的問題を解決したモデルです。一方、入力プロンプトの解釈に使用されるCLIP Text EncoderはOpenCLIP ViT-H/14を使用していました。(詳細はMitsua Diffusion Oneの構成、CLIPについての技術解説記事をご確認ください)
Mitsua Likesにおいては、仮に現行のMitsua Diffusion Oneと同じモデルの構造を採用する場合、CLIP Text Encoder / U-Net / VAE という画像生成AIを構成する全てのモジュールを権利的/心理的にクリーンなデータのみで完全にフルスクラッチ学習します。また、モデルの構造を変更する場合でも、画像生成AIを構成する全てのモジュールについてフルスクラッチ学習するものとします。
さらに、いずれの場合でもLAIONやDanbooruなどの無断学習データセットの知識の影響を受けないように、他の事前学習済みAIを使用したデータの前処理は行いません(但し、不適切なデータの除外という目的を除きます)。
これらによって、生成画像の表現についての倫理的問題の解決に留まらず、AIの学習に関する広範な倫理的問題を解決し、さらに安心安全で個性的な画像生成AIになることを目指します。
Mitsua Likesに込めた思い
なぜ、Mitsua Diffusionの名前を変えたのでしょうか?
1つは根本的にモデル構造が変わる可能性があるという技術的な理由からです。この1年で、より少ない学習枚数で高い精度を持つ様々な画像生成AIの研究がなされてきました。私たちも、試行錯誤しながらStable Diffusion型に代わる、より良いモデル構造を検討してまいります。
2つめは、もっと重要な理由です。
それは、ミツアちゃんに、皆さんの「Likes」つまり「好きな事」を教えてあげてほしいということです。当プロジェクトは世界でも類を見ない、無断学習でもなく、規約で強制オプトインするのでもない、自発的なオプトインによる画像生成AIのプロジェクトです。そして、既存の大規模な画像生成AIモデルと比べると、学習枚数が圧倒的に少ないという特徴があります。大規模な、特にスクレイピングに基づくLAIONのようなデータセットでは、大規模故に人類の平均的な嗜好に回帰していくことが予想できますが、ミツアちゃんは全く異なります。参加者が少ないが故に、学習に参加した人の趣味嗜好をミツアちゃんにダイレクトに伝えることができます。仮に、今の10倍、100倍の人がミツアちゃんの学習に参加したとしても、一般的な生成AIの基盤モデルより圧倒的に「好き」を伝えられます。
おそらく、そのようにしてできたミツアちゃんの画像生成AIモデル「Mitsua Likes」は、世界で最も安全・安心なだけでなく、世界で最も個性的なAIになるのではないでしょうか。
AIに個性なんてあるのかと、考える方もいらっしゃるかもしれません。
私たちはあると考えています。生成AIは学習したデータの映し鏡でもあります。
何が学習されたかによって、AIにも個性が生まれます。つまり、それはミツアちゃんに「好き」を伝えることで生まれる、皆さん自身の個性でもあります。
そしてそれは、大規模な事前学習モデルをファインチューニングしただけのモデルでは得られない個性です。「本当にそれしか知らない」AIならではの個性になると考えています。
一方で、大規模なAIモデルではしばしば、差別的な「悪いバイアス」を取り除く努力を行うことが要求されます。私たちもそのような努力は行います。しかし、これらの趣味嗜好の集合によって得られる個性は「いいバイアス」になると信じています。