11月1日、NTTグループは大規模言語モデル(Large Language Model・略称LLM)「tsuzumi」を発表した。LLMはChatGPTなど、文章を生成するAIアプリケーションで使われる技術である。
ChatGPTはじめ、多くのLLMは海外製であり、日本語の扱いがそこまで上手いわけではなかった。ChatGPTでも、日本語で使ったときと、英語で使ったときでは、回答の品質に大きな差を感じることは多い。そこで、日本語圏のユーザーには、日本語を深く理解し、日本にまつわる知識を備えたLLMの登場が待ち望まれていた。
PANORA読者なら、AITuberと呼ばれる、AIがまるでVTuberのようにコメントを読みしゃべる形式のコンテンツに興味を持っている人も少なくないと思うが、AITuberに使われているのもLLMだ。やはり、日本語でキャラクターらしい会話ができるLLMは多くの開発者が求めていると言っていい。
そうした需要が高まる中、NTTから日本語に強いLLMが発表された。記者会見にはNTTグループの社長と研究企画部門長の執行役員が登場し、NTTとしての意欲を感じさせるものだった。
リリース時点ではBtoB向け
和楽器の一つである鼓(つづみ)からその名前をとったtsuzumiは、2024年3月リリース予定。発表の中で明らかになったのは、コールセンターや医療、金融など、セキュリティが厳しい企業に対してのインテグレーションを想定しているということだ。ChatGPTのように、個人開発者やベンチャー企業が利用出来る形での展開は、リリース時点では想定されていないようだった。
7B(70億パラメーター)サイズという、LLMの中では比較的軽量な部類に入る大きさでありながら、GPT-3.5-Turboに比肩する性能を発揮するという。サイズが小さいというのは、消費電力や必要な処理能力が少なくて済むということでもあり、使いやすいということだ。その分、サイズが下がれば性能も下がるのが常だったが、サイズが小さくても十分な性能を発揮するということで、注目が集まっているというわけだ。
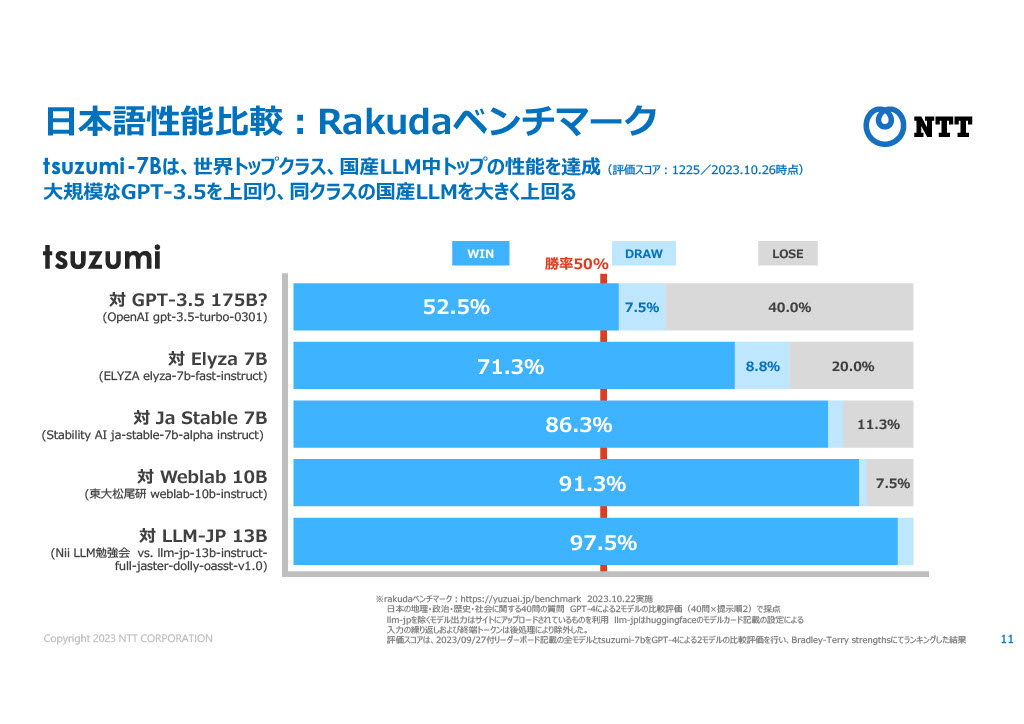
個人やベンチャーがtsuzumiを使えるようになるのは先の話かもしれないが、いくつか、LLMやAITuber開発において参考になりそうな知見も披露されていたので、その辺りを中心に紹介したい。
自然言語処理研究に強いNTTならではのノウハウ
NTTは電話会社という認識も強いかもしれないが、実は日本最大手の研究機関の一つでもある。AIや言語処理の分野でも大きな成果を上げており、AI分野での論文数は日本1位・世界12位、自然言語処理分野でも日本一の実績を誇ることが説明されていた。

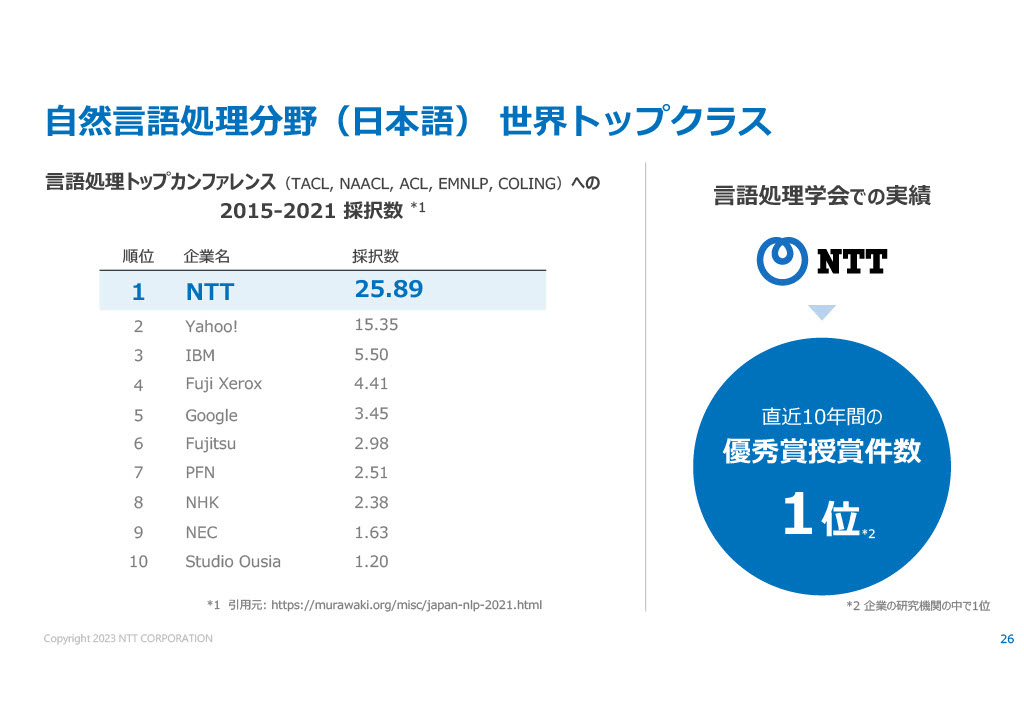
なによりも、NTTは研究機関としての長い実績があり、社内には様々なデータやノウハウが蓄積されているという。木下部門長が質疑応答時に、研究者でさえすべてを挙げきれないような明文化・形式化されていないノウハウを、歴代の先輩から引き継いでいるといった主旨の返答をしていた。
LLMの開発には、まずは大量のデータを集めて事前学習と呼ばれる最初のモデル構築を行い、その後、チューニングしていくというプロセスをとる。特に、インストラクションチューニングと呼ばれるチューニングプロセスでは、NTT内製のデータも活用されており、性能と共に倫理性、安全性も高めているとのことだった。

こうした、学習させたデータの品質の高さが、tsuzumiの性能の高さに繋がっているとのことだった。LLM開発者の間でも、データ品質は頻繁に議論になるテーマである。tsuzumiの性能がアナウンスされたとおり高いものならば、今後、より学習データへの注目が高まっていくことが予想される。
NTTグループ各社は研究成果を、論文のほか勉強会やGithubでのコード公開などといった形でも公開しているので、個人開発者やベンチャー企業も参考にすることが出来るかもしれない。
マルチアダプタで多様な用途に対応
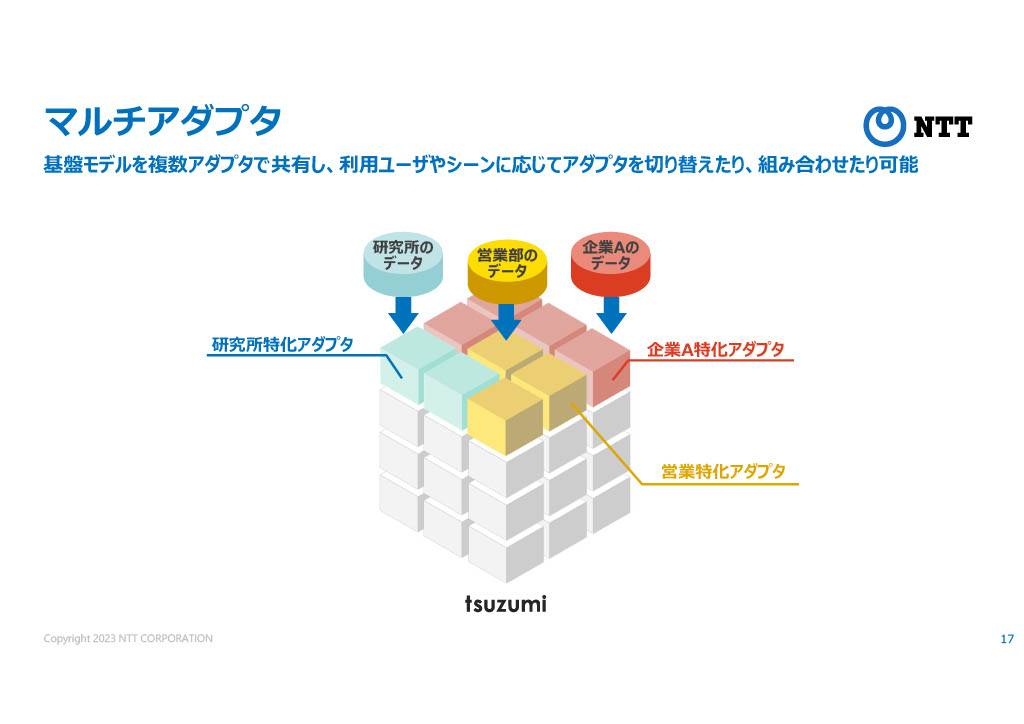
今後のLLM開発でも注目されそうなアプローチとして、マルチアダプタが紹介されていた。基礎となるモデル(基盤モデル)に対して、特定の用途に特化したチューニングデータをアダプタのように取り付けることができる。すでに、画像生成AIや多くのLLMでもLoRA(Low Rank Adaptation)などの形で実装されている考え方だが、よりアプリケーションに近い側で整備されていくことに期待が持てる。
遠隔GPUクラウドの利用、複数LLMの連動
NTTはIOWNと名付けられた次世代の光通信技術に大きな投資をしているが、そのIOWNを用いて、横須賀と三鷹の研究所を繋いでLLMのトレーニングを行ったという。
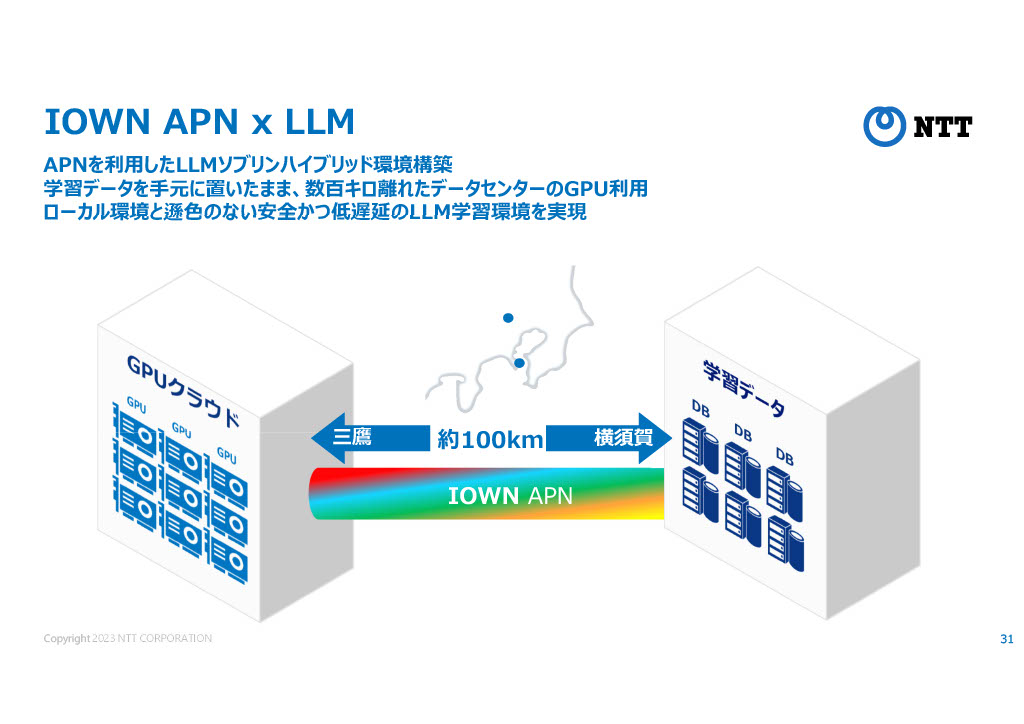
IOWNによる高速な通信網を用いて、複数のLLMを連携させる将来的な構想も持っているとのことだった。
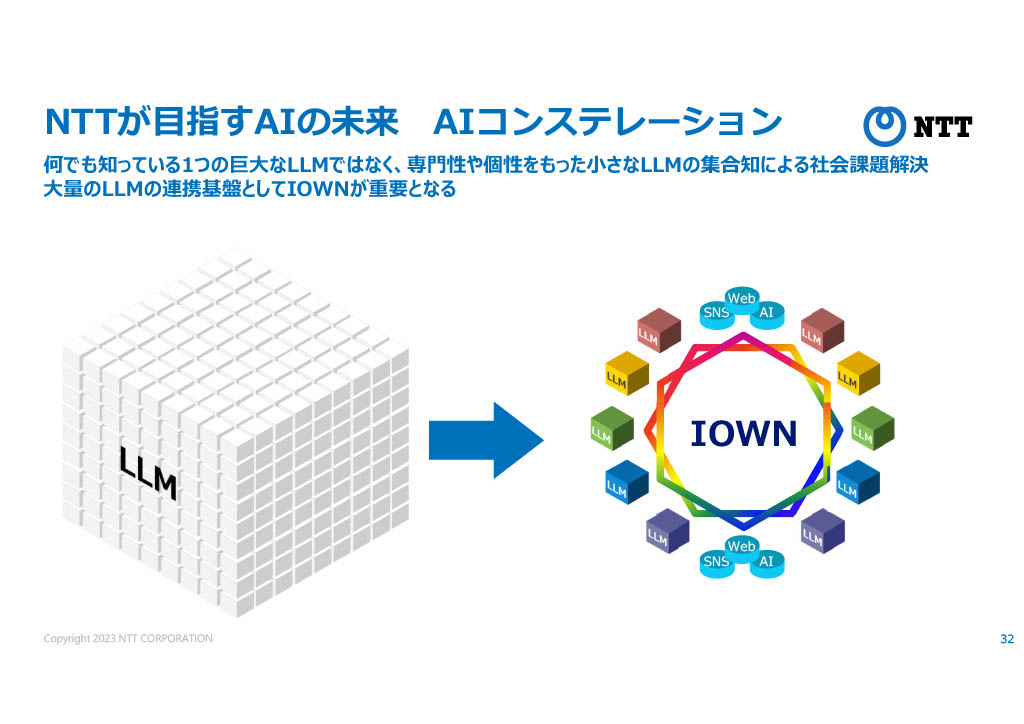
こうしたアプローチも、LLM開発の発展に影響がありそうで、注目していきたい。
サービス開始は2024年3月から。マルチモーダルや13Bサイズ以上の展開も予定
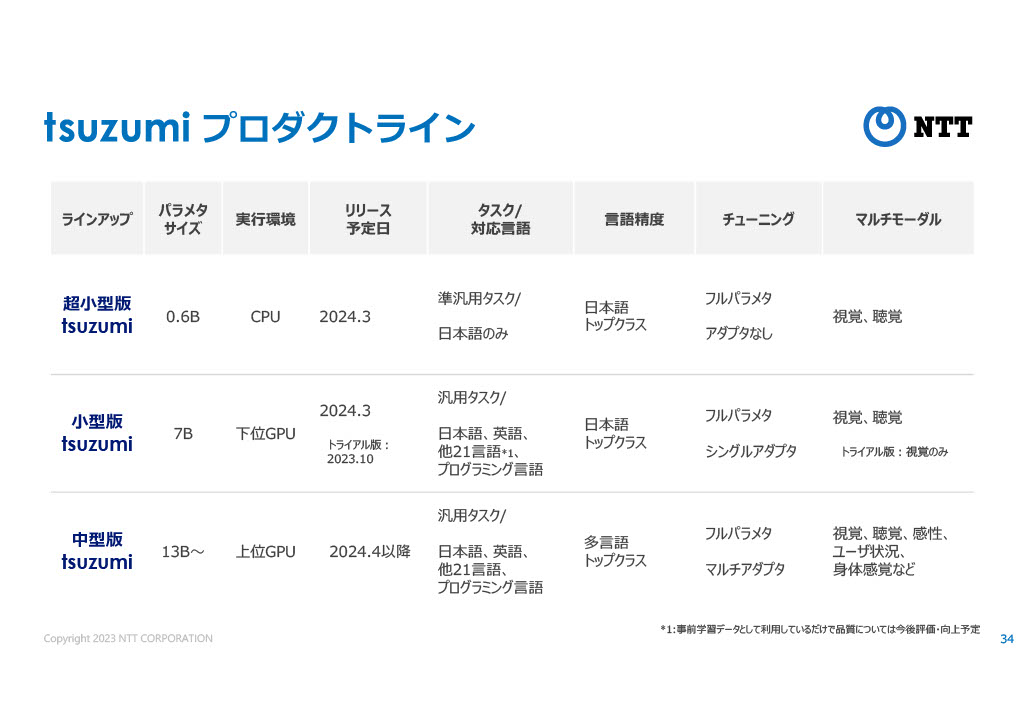
tuzumiは超小型版の0.6Bサイズと、小型版の7Bサイズが2024年3月からリリースされる予定だ。記事冒頭で述べたとおり、BtoBソリューションとしての展開となる。
また、文字情報だけでなく、画像(視覚)や音声(聴覚)も入力することができるマルチモーダルも展開予定とのこと。13B以上の中型版も来年度以降に計画されている。
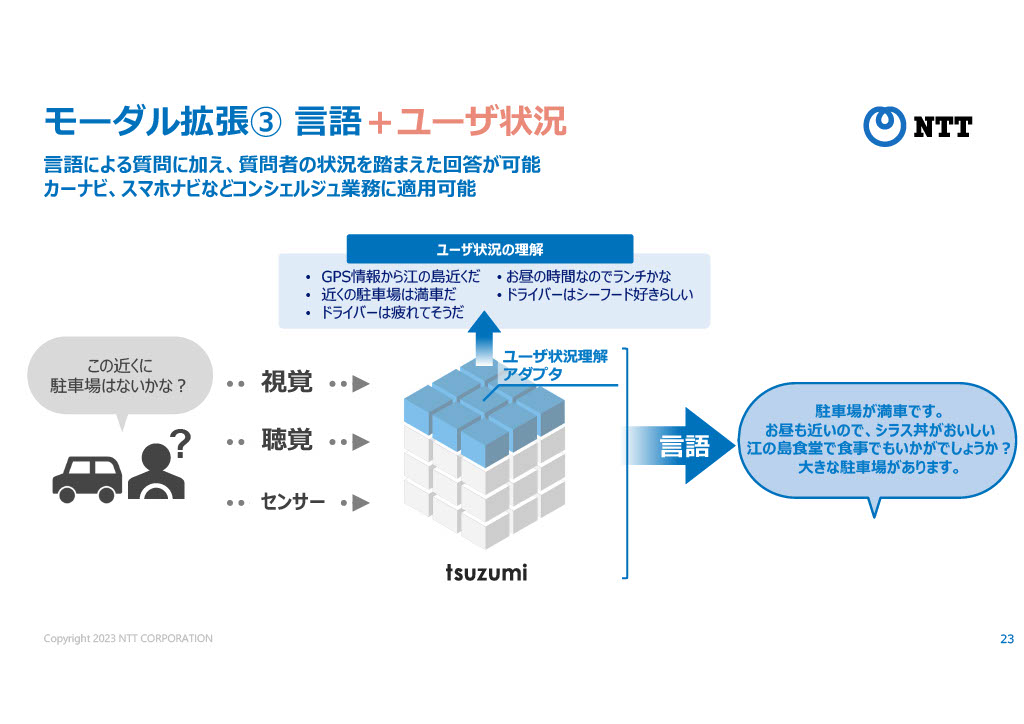
マルチモーダルでは、視覚や聴覚だけでなく、各種センサーで取得した慣性、ユーザーの置かれた状況、身体感覚なども入力情報にできる構想がある。
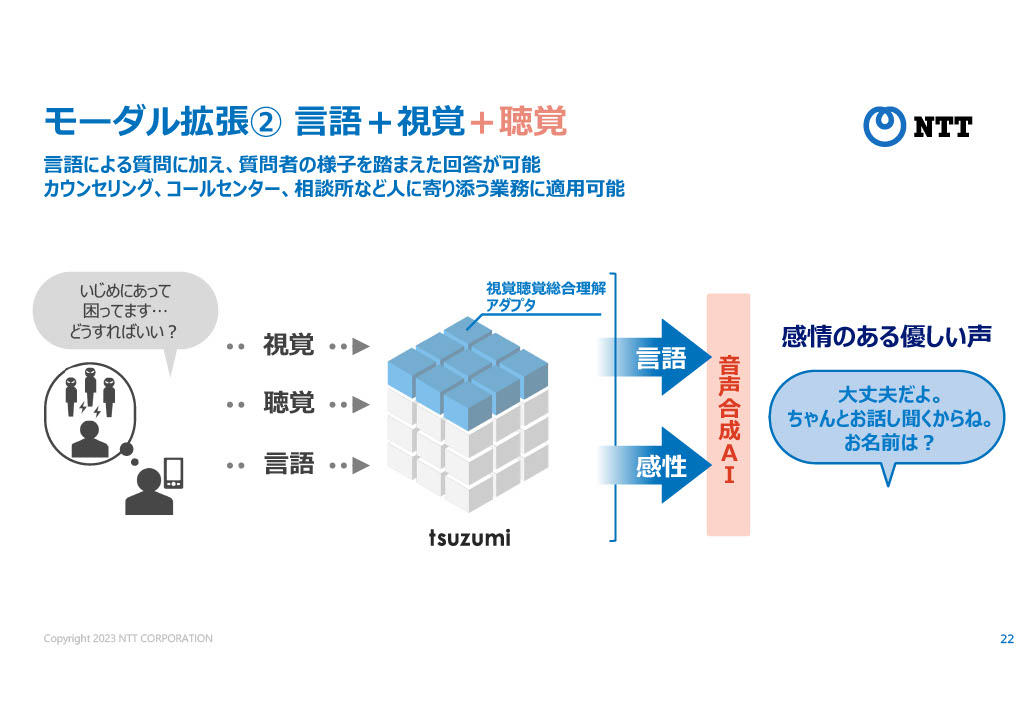
木下部門長は例として、ドライブしていたらその土地の情報や走行状況なども加味した返答をするAIや、子供が相談の電話をかけてきたときにその声色から対応を変えていくAIなどを挙げていた。
詳細な議論はNTT R&Dフォーラムでも
NTTは毎年、R&Dフォーラムという、研究成果発表イベントを実施しており、今年も11月14日から開催される。オンラインならば誰でも登録して視聴可能なので、より踏み込んだ内容を聞いてみたい人は、参考になるかもしれない。
(Text: 松xR)